728x90

오늘은 광주인공지능학원에서 진행된 알파벳 맞추기를 진행하겠습니다
(본 글의 자료는 광주인공지능학원에서 제공되었습니다.)
CNN 입력값 파라미터
- (sample, height, weight, chanel)
- sample: 데이터의 수
- height: 세로
- weight: 가로
- chanel: 1 (grayscale) 3 (RGB) 4(RGBA) * A 투명도
RNN 파라미터
- (sample, timesteps, features)
- sample: 데이터의 수
- timesteps: 몇 단계로 이루어 질것인지
- 내일 주식가격 예측을 위해서 과거 5일의 데이터를 가져옴: 5
나는 오늘 집에 가서 밥을 __: 5
- features: 특징의 수
- 예를들어) 음악: 미 레 도 레 _ 음계: features: 1 음계, 박자: features: 2
문제) 다음주 에너지 사용량 맞추기
- 사용되는 데이터는 이전 4주차 에너지 데이터
- 에너지가 사용되는 건물 전체의 에너지 데이터
- 총 20명 학생에게 데이터를 받아옴
답)
sample: 20
timestep: 4
features: 1
SimpleRNN 사용하기
- hello
- hell을 썼을때 o를 맞추는 모델
- 과거 4개의 char를 이용해서 다음에 등장할 char를 예측하는 모델 만들기
hello, apple, lobby, daddy, bobby, holly, bubbl, olleh각 char를 원 핫 인코딩으로 수치화 시키자
- h, e, l, o, a, p, b, d, y, u
- 총 10개 단어 사용
- feature: 10개
원핫 인코딩을 시키면
- h: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- e: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- l: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
- o: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
- a: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
- p: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
- b: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
- d: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
- y: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
- u: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
import numpy as np
다음과 같이 단어에 마지막 알파벳을 제외한 알파벳을 배열로 만들어줍니다.
hello, apple, lobby, daddy, bobby, holly, bubbl, olleh
X_train = np.array([[
[['h'],['e'],['l'],['l']],
[['a'],['p'],['p'],['l']],
[['l'],['o'],['b'],['b']],
[['d'],['a'],['d'],['d']],
[['b'],['o'],['b'],['b']],
[['h'],['o'],['l'],['l']],
[['b'],['u'],['b'],['b']],
[['o'],['l'],['l'],['e']]
]])
그후에
- h: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- e: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- l: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
- o: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
- a: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
- p: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
- b: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
- d: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
- y: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
- u: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
이 위에 써진대로 알파벳을 벡터형식으로 바꿔줍니다.
X_train = np.array([
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]],
[[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0]],
[[0, 0, 0, 0, 0, 0, 0, 1, 0, 0],[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 1, 0, 0],[0, 0, 0, 0, 0, 0, 0, 1, 0, 0]],
[[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0]],
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0]],
[[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]]
])
정답값인 y값도 똑같이 벡터로 바꿔줍니다.
여기서 정답값이란 hello에서의 o입니다.
apple에서는 e, lobby에서는 y 등
y_train = np.array([
[ 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[ 0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[ 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
X_train.shape, y_train.shape저랑 똑같은 단어로 똑같이 만들었다면 X_train, y_train의 행렬은 위와 같아야 합니다.
반응형
그럼 이제 딥러닝 모델을 만들겁니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
# hello, apple, lobby, daddy, bobby, holly, bubbl, olleh
model = Sequential()
# timesteps: 4
# features: 10
# 입력, 은닉
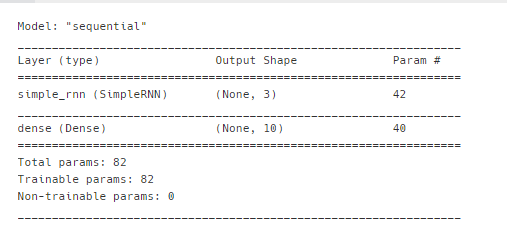
model.add(SimpleRNN(3, input_shape = (4, 10))) # sample, (timestep, features)
# 출력
model.add(Dense(10, activation = "softmax")) # 다중분류
model.summary()
# 컴파일
model.compile(loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])history1 = model.fit(X_train, y_train, epochs = 800, batch_size=30)
저는 일단 간단한 연습이기 때문에 반복은 800만 잡아줬습니다.
만들어진 모델로 예측을 진행해봅시다.
# 예측
# 문제: apple
# 정답: e > [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] > class: 1
model.predict_classes([[[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]]])
예측이 결과가 1이 나올걸 보니 예측이 잘된걸 확인할 수 있습니다.
다음은 반복횟수별 train의 예측값이 얼마나 나온지를 확인할 수 있습니다.
import matplotlib.pyplot as plt
acc = history1.history['accuracy']
# val_acc = history1.history['val_accuracy']
epoch = range(1, len(acc)+1)
plt.plot(epoch, acc, c = 'red', label = 'Train acc')
# plt.plot(epoch, val_acc, c = 'blue', label = 'Test acc')
plt.legend()
plt.plot()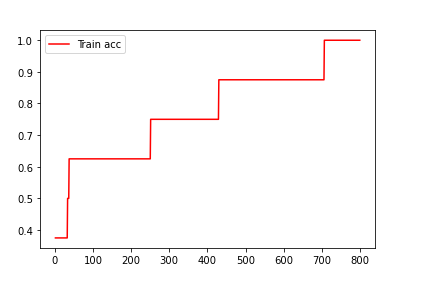
더 자세한 사항은 광주인공지능학원에서!!
광주인공지능학원에서 진행된 수업을 기반으로 작성되었습니다.
[광주인공지능학원 링크]

728x90
'파이썬 > 딥러닝' 카테고리의 다른 글
| [광주인공지능학원] CNN (합성곱 신경망) (0) | 2021.08.16 |
|---|---|
| [딥러닝][광주인공지능학원] 딥러닝 실습 - 와인 데이터 & 폐암환자 데이터 (0) | 2021.08.01 |
| [딥러닝] [광주인공지능학원] 딥러닝 기초 실습 (0) | 2021.08.01 |
| [딥러닝] 딥러닝 기초 [광주인공지능학원] (0) | 2021.07.26 |
| [딥러닝] 딥러닝의 역사 [광주인공지능학원] (0) | 2021.07.25 |