728x90

오늘은 딥러닝의 개념, 역사를 소개 할겁니다.
딥러닝을 공부하기 전에 간단히 이제까지 배운것들을 정리하겠습니다.
1. 인공지능과 머신러닝 딥러닝의 차이점
인공지능
- 사람같은 기계를 만드는것이다.
- 약한 인공지능은 사람보다 부족하고
- 강한 인공지능은 사람보다 뛰어나다
머신러닝
- 정답을 학습시키고 평가하여 학습시키지 않은 것들 예측하는 것
딥러닝
- 정답을 학습시키지 않고 기계락 스스로 학습하게 하는것
2. 머신러닝 학습 순서와 간단한 개념
머신러닝 : 학습순서는 특성 -> 모델 -> 라벨 예측
- 특성(feature) = data. 입력 문제
- 라벨(label)= 답 출력
- 클래스: 라벨의 종유(생존/ 사망 – 2개)
범주형 데이터의 종류를 표현하는게 클래스 - 범주형 데이터: 문자 데이터 & 연속적이지 않은 기호 형태의 숫자데이터. 데이터가 범주화 되어있는 데이터 ( 예를 들어 고양이과에는 사자, 고양이, 여우 등이 포함되어있다. 예2 성적이 90점대 80점대 70점대…)
- 수치형 데이터: 연속적인 데이터, 크기를 갖는 숫자로 된 데이터
회귀분석: 수치형 데이터 사용
분류분석: 범주형 데이터 사용
라벨 인코딩/ 원핫인코딩
- 범주화 -> 수치화
- 라벨 인코딩: 범주형 데이터를 정수로 바꾸는 것 (실수로 바꿀수도 있긴하다)
replace(a,b) 와 map({“a”:”b”}) - 원핫인코딩: spare(2진수중에 1이 아주 작은 데이터)한 데이터로 변환
<->Dense(밀집)
범주형데이터를 이진수로 변환한다.
원핫 인코딩 장점
3. 지도학습/ 비지도 학습/ 강화학습 개념
1. 지도 학습: 데이터에 특성과 라벨이 모두 주어진 것(특성 -> 라벨)
- 특성 -> 학습(규칙.수식) - > 모델 -> 라벨
분류 – 라벨이 범주형(이진, 다진)
회귀 – 라벨이 수치형 - 문제점: 라벨을 붙여야 한다. 주관성이 강하다.
2.비지도 학습: 데이터에 특성만 주어진 것
- 특성분석을 통해 시각화, 압축, 특성추출(차원축소 -> 데이터 크기 감소)
- 군집: 그룹핑 = 비슷한 특성끼리 묶어서 라벨링 하는 것
특징(확률밀도함수)
3. 강화학습: action(벌칙 - , 보상 +) 가장 큰 보상을 주는 action을 선택
4. 과대적합/ 과소적합/ 일반화 개념
- 훈련: 학습하는데 쓰는 데이터 fit( )
- 테스트: 모델을 평가하기 위한 데이터
- 검증: 평가한 모델에 넣어주는 실제 데이터
- Train >> test -> 과대적합
- Train =< test 또는 train, test ↓ => 과소적합
- 위의 과대적합, 과소적합이 아니면 일반화
- 과대적합: 특성이 많거나 복잡할 때 발생, 데이터가 적다
해결방법: 특성선택, 차원축소 - 과소적합: 특성이 적거나 간단할 때 발생, 데이터가 너무 적다
해결방법: 비지도 학습, 특성추출, 데이터 수집
5. 머신러닝 모델 프로세스
머신러닝 프로세스
- 문제정의
- why, what, how, 데이터?, 모델? -> 기획 - 데이터수집 ★
- 데이터 저장/관리
- 크롤링, 공공데이터, API, 설문조사(survey), 센서데이터, 자체제작 - EDA(탐색적 데이터 분석) ★★★
- 결측치, 이상치, 오타, 기술통계, 시각화, 표 등 - 데이터 전처리(특성 공학) ★★
- 데이터에 대해서 잘 알아야 한다. (해당 전공자 필요)
- 특성들을 수정, 개선, 추가, 삭제, 변환
- 학습하기 최적화된 데이터로 만들어준다. - 모델선택
- 모델선택 및 하이퍼파라미터 최적화(튜닝) - 학습
- 평가(MSE, 정확도, recall, precison, f1 score)
- 회귀: 오차(실제값 – 예측값)의 평균/ 합 -> 음수 때문에 평가가 잘되지 않음
따라서 절대값(MAE), 제곱(MSE)을 사용. 제곱(MSE)을 더 많이 쓴다.
제곱(MSE)은 오차의 크기를 크게 하여 분류가 쉽게함 -> 원래로 돌림 -> RMSE
오차€/편차(R2스코어)를 적용하여 판단.
- 분류: 정확도, 정밀도, 재현율, f1 score - 예측
여기까지가 이제까지 배운 내용을 간단히 정리한 것이었고
이제는 딥러닝에대한 개념, 역사 등을 소개 하겠습니다.
딥러닝 간단한 개념
라이브러리
- 텐서플로우(tensorflow)라이브러리 사용
- 1차원 데이터 -> vector
- 2차원 데이터 -> array, Matrix
- 3차원 데이터 -> tensor
- 조금 더 쉽게 keras 라이브러리
- Py torch: 조금 더 세부적 제어가 가능(전문)
- linex
모델 설계
- 전이 학습이라고 이미 만들어진 모델을 사용할 수도 있다.
딥러닝의 역사

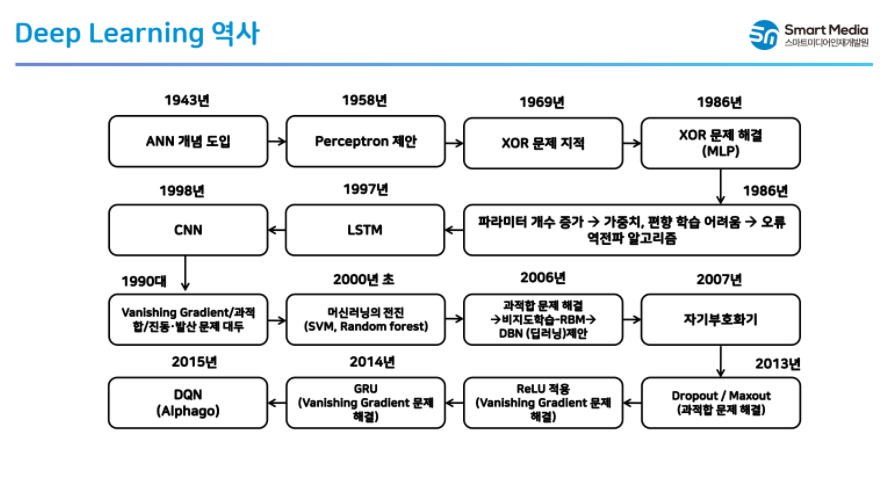
1990년대 까지의 딥러닝
- 선형(L, R) 모델을 사용
선형회귀의 단점(문제점)
- 데이터가 많아지면 특성이 많아져서 과적합이 발생한다.
- 연산 시간이 많이 걸린다.
- 시그모이드 함수를 사용하다 보니 기울기가 0이 되는 현상 발생
이런 문제점 때문에 머신러닝이 부각
2006년 딥러닝 제안한 제프리 힌튼 덕분에 과적합 문제를 해결하고 딥러닝이 다시 부광하였다.
이때 우리가 아는 딥러닝이라는 명칭을 사용하게 되었다.
AlexNet
- 활성함수로 시그모이드나 tanh대신 ReLU를 사용하여 속도 개선
Dropout / Maxout
- 과적합 해결
DQN/ FCN/ ReNet/ DeepLab
- 이세돌을 인공지능이 이기면서 딥러닝이 열광
BERT
- 문장을 분해하여 중요한 부분만 추출하여 새로운 문장을 만들어준다.
시나 대화 가능


스마트인재개발원에서 진행된 수업내용입니다
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
728x90
'파이썬 > 딥러닝' 카테고리의 다른 글
| [딥러닝] Simple RNN 단어의 다음 알파벳 맞추기 [광주인공지능학원] (0) | 2021.08.22 |
|---|---|
| [광주인공지능학원] CNN (합성곱 신경망) (0) | 2021.08.16 |
| [딥러닝][광주인공지능학원] 딥러닝 실습 - 와인 데이터 & 폐암환자 데이터 (0) | 2021.08.01 |
| [딥러닝] [광주인공지능학원] 딥러닝 기초 실습 (0) | 2021.08.01 |
| [딥러닝] 딥러닝 기초 [광주인공지능학원] (0) | 2021.07.26 |