아래는 제가 쓴 코드에서 필요한 임폴트들인데요.
이거 전부를 임폴트할 필요는 없어요. 제가 사용할때는 전부 다 필요했지만 티스토리에는 시행착오 전부를 적을게 아니라 일부만 적을거기 때문에 중간중간에 sklearn빼고 파이썬 내장라이브러리가 아닌것들은 다운받지 않으셔도 됩니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_files # 파일읽어오기
import KnuSentiLexMaster
from KnuSentiLexMaster.knusl import KnuSL # 한국어 사전 임폴트 연습
import tensorflow as tf # 텐서플로우
from tensorflow import keras # 케라스(Keras)
import gensim # 젠심(Gensim)
import sklearn
from konlpy.tag import Okt
from konlpy.tag import Kkma
from soynlp.normalizer import * # 반복되는 문장제거
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
# svm
from sklearn.svm import LinearSVC
# 교차검즘
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# pipeline: 토큰화 + 모델학습
from sklearn.pipeline import make_pipeline
# TfidfVectorizer(tf-idf) 토큰화
from sklearn.feature_extraction.text import TfidfVectorizer
# 정확도 검사
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from tqdm import tqdm
import re
from sklearn.svm import LinearSVC
from sklearn.model_selection import GridSearchCV1. 수기 라벨링 머신러닝
먼저 수기단 라벨링은 정답데이터로 머신러닝을 돌린걸 설명해 드리겠습니다.
data = pd.read_csv("data/댓글라벨링.csv", encoding="cp949")
data
문제와 정답을 분류
# 문제와 정답 분류
X = data['댓글'] # 문제
y = data['긍정부정'] # 정답
# train, test 분류
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3, random_state=34)
1-1. CountVectorize 토큰화
처음에는 CountVectorize 토큰화를 사용해 보았어요.
훈련 데이터를 학습 시킵니다.
# 토큰화
CV = CountVectorizer()
CV.fit(X_train) # 토큰화, 단어사전 구축
문제 데이터를 벡터화 시켜주세요.
CountVectorize 토큰화는 텍스트에서 단위별 등장횟수를 카운팅하여 수치벡터화 합니다.
단위는 단어, 문장, 문서등을 고를 수 있는데 디폴트는 단어 단위에요.
# 수치화(벡터화)
# 문제 데이터
X_train = CV.transform(X_train)
X_test = CV.transform(X_test)
토큰화를 해주었으니 이제 모델을 선택합니다.
1-1-1. LinearSVC 모델
LinearSVC 모델을 사용하여 토큰화된 데이터를 학습 시켰어요.
svm = LinearSVC()
svm_result = cross_val_score(svm, X_train, y_train, cv=5)
svm_result.mean()
모델을 학습 시키고 정확도를 계산했는데 정확도가 0.67밖에 나오질 않았답니다..
# 0은 부정, 1은 긍정, 2는 중립
svm.fit(X_train, y_train)
# 정확도
labels = y_test # 실제 labels
guesses = svm.predict(X_test) # 예측된 결과
print(accuracy_score(labels, guesses))

1-1-2. LogisticRegression 모델
다음으로는 LogisticRegression 모델을 사용했습니다.
logi = LogisticRegression()
logi.fit(X_train, y_train)
print("Accuracy: {}".format(logi.score(X_test, y_test)))
LinearSVC 모델보다는 점수가 올랐지만 그래도 너무 낮아요....
그래서 토큰화 방법을 바꿔줬어요.
1-2 TfidfVectorizer(tf-idf) 토큰화
tfidf = TfidfVectorizer()
tfidf.fit(X)
# 토큰화
tfidf_transform = tfidf.transform(X).toarray()
1-2-1. LinearSVC 모델
# svm 모델 사용
pipe = make_pipeline(TfidfVectorizer(), LinearSVC())
pipe.fit(X_train, y_train)
labels = y_test # 실제 labels
guesses = pipe.predict(X_test) # 예측된 결과
print(accuracy_score(labels, guesses))
tf-idf 토큰화도 결과가 좋지 않았어요.
그래서 수기 라벨링 데이터를 사용하는것도 포기했습니다.
2. 직접만든 단어사전으로 라벨링후 머신러닝
다음으로 직접 만든 긍정, 부정 단어사전으로 라벨링을 했습니다.
아래 긍정단어, 부정단어는 웹툰 댓글들을 보면서 긍정적인 댓글에 주로 나오는 단어와 부정적인 댓글에 주로 나오는 댓글을 직접 판단하여 작성한 것으로 사람마다 주관적으로 판단이 다를 수 있고 웹툰 댓글이 아닌 다른 문장에는 적용할 수 없을 수 있습니다.
positive = pd.read_csv("data/긍정단어.csv", encoding="utf-8")
negative = pd.read_csv("data/부정단어.csv", encoding="utf-8")
negative = negative['부정단어']
positive = positive['긍정단어']
직접 만든 단어사전으로 라벨링은 38만개 댓글 모두에 적용시킬겁니다.
따라서 전체 댓글 데이터를 가져옵니다.
# 전체 38만 댓글
comment38 = pd.read_csv("전처리후데이터/댓글데이터fin.csv", encoding="cp949")
comment38.drop("Unnamed: 0", axis=1, inplace = True)
comment38.head(1)
labels = []
for comment in tqdm(comment38['댓글']):
# 특수문자 제거
# comment = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…\"\“]', '', comment)
negativeFlag = False
label = 2 # 디폴트로 중립
for i in range(len(negative)):
if negative[i] in comment:
label = 0 # 부정
negativeFlag = True
print(f"부정 비교단어 : {negative[i]}, 댓글: {comment}")
break
if negativeFlag == False:
for j in range(len(positive)):
if positive[j] in comment:
label = 1 # 긍정
print(f"긍정 비교단어 : {positive[j]}, 댓글: {comment}")
break
labels.append(label)
comment38['단어모음라벨'] = labelslabel이라는 변수는 처음에 2로 두고 (저희는 2를 중도 댓글로 하기로 했어요) 만약 문장에 부정 단어가 있으면 label을 0으로 바꾸고 부정 단어를 모두 비교한후 긍정단어가 있으면 label을 1로 바꾸는 식으로 코드를 작성했습니다.
그리고 label을 labels라는 리스트에 담고 이 리스트로 단어모음라벨이라느 컬럼을 만들었어요.

이제 직접만든 단어사전을 이용하여 라벨링을 진행했으니 기를 기반으로 머신러닝을 돌릴건데요.
머신러닝은 앞에서 사용한 토큰화와 모델을 사용해보았기에 가장 예측률이 높았던것만 소개하겠습니다.
2-1. CountVectorizer토큰화 & LinearSVC 모델
순차적으로 예측하기
예측된 단어를 컬럼에 저장할거라서 순서를 섞지 않게 shuffle=False 파라미터를 작성하여 순차적으로 train, test에 담았습니다.
X = comment38['댓글'] # 문제
y = comment38['단어모음라벨'] # 정답
# train, test 분류
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
shuffle=False,random_state=34)
토큰화와 모델을 한번에 학습 시키기 위해서 pipeline을 사용했어요.
# pipeline : 토큰화, 모델학습
pipe = make_pipeline(CountVectorizer(), LinearSVC())
pipe.fit(X_train, y_train)
예측 정확도는 이제까지 중에서 제일 높았습니다.
# make_pipeline(CountVectorizer(), LinearSVC()) 정확도
labels = y_test # 실제
guesses = pipe.predict(X_test) # 예측
print(accuracy_score(labels, guesses))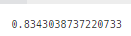
파이프라인으로 예측된 결과를 변수에 담고 예측된 결과를 가지고 예측 라벨이라는 컬럼을 만들어 줍니다.
그리고 이를 댓글예측완료2라는 csv파일로 만들어 줬어요.
X_train55 = pipe.predict(X_train)
X_test55 = pipe.predict(X_test)
train_test = np.concatenate((X_train55, X_test55), axis = 0)
comment38['예측라벨'] = train_test
comment38.to_csv("댓글예측완료2.csv", encoding="")
이제부터는 각각의 웹툰을 가지고 단어 구름을 만들어 볼겁니다.
그리고 저는 단어구름을 만들고 이미지를 단어구름이미지3라는 폴더에 저장 시킬거라서
단어구름이미지3라는 폴더를 바탕화면에 만들어 주는 코드르 작성해요.
이미 폴더가 있으면 안되니 조건문으로 확인해줍니다.
import os
if not os.path.isdir("C:/Users/SM2119/Desktop/단어구름이미지3") :
print('폴더 생성 완료')
os.mkdir("C:/Users/SM2119/Desktop/단어구름이미지3")
else:
print("이미 동일한 이름의 폴더가 있습니다")
각각의 웹툰별로 & 회차별로 & 긍정부정을 구별해서 만들어 줬어요.
어떤 웹툰은 부정댓글이 하나도 없어서 단어구름을 만들어줄 문장이 없어 오류가 나기 때문에 예외처리문을 작성해 줍니다.
# 긍정 부정 구분
# 웹툰 1~5화 안합친거
num = 0
for i in comment38.웹툰제목.unique():
for j in comment38[comment38.웹툰제목==i].회차.unique():
for n in range(0,2): # 예측라벨
try:
text = comment38[(comment38.웹툰제목==i)&(comment38.회차 == j)&(comment38.예측라벨==n)].댓글.tolist()
text = ' '.join(text).lower()
wordcloud = WordCloud(font_path='NanumGothic.ttf',background_color='white').generate(text)
plt.imshow(wordcloud, interpolation='bilInear')
plt.axis('off')
if n == 0:
result = "부정"
elif n == 1:
result = "긍정"
plt.savefig('C:/Users/SM2119/Desktop/단어구름이미지3/'+new_string[num]+str(j)+"화 "+result+'.png')
num += 1
plt.show()
except:
continue

댓글이 너무 없을 경우 아래처럼 나옵니다.

이글은 광주인공지능학원(스마트인재개발원)에서 진행된 프로젝트 내용입니다.
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
'프로젝트' 카테고리의 다른 글
| 웹툰 승격 확률 예측 시스템 프로젝트 - kosac사전을 이용한 감정분석 [광주인공지능학원] (0) | 2021.07.11 |
|---|---|
| 웹툰 승격 확률 예측 시스템 프로젝트 - 크롤링2 [스마트인재개발원] (0) | 2021.07.04 |
| 웹툰 승격 확률 예측 시스템 프로젝트 - 크롤링1 [스마트인재개발원] (0) | 2021.07.04 |