Decision Tree(결정트리)
- Tree를 만들기 위해 예/아니오 질문을 반복하며 학습
- 분류와 회귀에 모두 사용가능
- 타깃 값이 한개인 리프 노드를 순수노드라고 한다.
- 모든 노드가 순수 노드가 될때 까지 학습하면 복잡해지고 과대적합이 된다.
- 새로운 데이터 포인트가 들어오면 해당하는 노드를 찾아 분류라면 더 많은 클래스를 선택하고, 회귀라면 평균을 구한다.
Decision Tree(결정트리) 과대적합 제어
- 사전 가지치기(pre-pruning) : 노드 생성을 미리 중단하는 방법
- 사후 가지치기(pruning) : 트리를 만든후에 크기가 작은 노드를 삭제하는 방법
- 트리의 최대깉이나 리프 노드의 최대 개수를 제어
- 노드가 분할 하기 위한 데이터 포인트의 최소 개수를 지정
주요 매개변수(Hyperparameter)
- DecisionTreeClassifier(max_depth, max_leaf_nodes, min_sample_leaf)
- 트리의 최대 깊이 : max_depth (깊이가 깊을수록 모델의 복잡도가 올라간다.)
- 리프 노드의 최대 개수 : max_leaf_nodes
- 리프 노드를 구성하는 최소 샘플의 개수 : min_sample_leaf
장점
- 만들어진 모델을 쉽게 시각화할 수 있어 이해하기 쉽다.
- 각 특성이 개별 처리되기 때문에 데이터 스케일에 영향을 받지 않아 특성의 정규화나 표준화가 필요없다.
- 트리 구성시 각 특성의 중요도를 계산하기 때문에 특성 선택에 활용될 수 있다.
단점
- 훈련데이터 범위 밖의 포인트는 예측할 수 없다. (ex 시계열 데이터)
- 가지치기를 사용함에도 불구하고 과대적합되는 경향이 있어 일반화 성능이 좋지 않다.
- 선형모형에는 적합하지 않다.
데이터 표현
- 숫자형(연속형) 특성 : 숫자로 이루어진 순서가 있는 데이터
- 범주형 특성 : 문자 형태로 된 값을 구분하기 위한 데이터
- Encoding : 범주형 데이터를 숫자형 데이터로 변환 (Label Encoding, One-hot Encoding, Word Embedding)
- Binning : 숫자형 데이터를 범주형 데이터로 변환
결정트리 모델을 이용하여 mushroom데이터를 분석해볼거다.
csv파일은 아래에 있다.
1. 문제 정의
- 버섯의 특징을 활용해 독/ 식용 버섯의 분류
- Decision tree 시각화 & 과대적합 제어
graphviz가 안깔린사람들은 !pip install graphviz를 실행해서 graphviz를 다운해주세요
import pandas as pd
from sklearn.model_selection import train_test_split
# 분류 tree
from sklearn.tree import DecisionTreeClassifier
# 회귀 tree
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
# !pip install graphviz
import numpy as np
# 교차검증을 위한 라이브러리
from sklearn.model_selection import cross_val_score
2. 데이터 수집
mush = pd.read_csv("mushroom.csv")
mush.head()
3. 데이터 전처리
- info : 결측치, 데이터 타입
- describe : 기술통계를 보여줌, 이상치확인하는데 사용
- 이상치를 확인할땐 데이터가 수치형 데이터여야한다.
- 따라서 지금 데이터에서는 수치형이 아니라서 이상치를 확인하기 어렵다.
먼저 결측치가 있는지 없는지 info로 확인해봤는데 이자료는 결측치가 없어서 결과창은 올리지 않았어요.
# 결측치 확인
# 결측치가 없는걸 확인할 수 있다.
mush.info()
describe
- 이상치를 파악하는데 쓰임
- count : 개수
- unique : 중복을 데거한 데이터 개수
- top : 가장많은 비율을 차지하는 데이터 개수
- freq : top의 실제 데이터
다음은 이상치를 확인하기 위한 기술통계인데 이상치가 없다고 판단해서 그냥 넘어가겠습니다.
mush.describe()
이제 모델에 학습시키기 위한 문제와 정답을 나눠보자
문제는 X, 정답은 y이다.
# 문제와 정답으로 나누기
# 문제 : 나머지
# 정답 : poisonous
X = mush.loc[:,"cap-shape" : "habitat"]
y = mush["poisonous"]
# shape를 이용해서 자료가 잘들어갔는지 확인
print(X.shape)
print(y.shape)
인코딩을 해보자. 인코딩은 여러 종류가 있는데 우리는 2가지방법을 써볼겁니다.
1. one-hot Encoding
- 0 or 1의 값을 가진 여러개의 새로운 특성으로 변경하는 작업
- 0과 1의 값을 가진 여러개의 새로운 컬럼을 만든다.
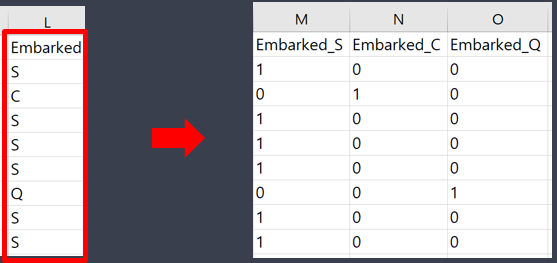
먼저 문제값인 X를 원핫인코딩
# 원핫인코딩 : get_dummies
X_onehot = pd.get_dummies(X)
# shape로 행열수 확인
X_onehot.shape
# train, test분류
X_train, X_test, y_train, y_test = train_test_split(X_onehot, y, test_size=0.3, random_state=3)
2. label encoding
- 단순 수치값으로 mapping
- 새로운 컬럼을 만들지 않고 기존 컬럼의 값을 문자에서 숫자로 변환한다.

라벨 인코딩을 이용하여 habitat 컬럼의 값을 문자에서 정수형으로 바꿔 줄겁니다.
먼저 unique함수로 habitat컬럼의 값들을 확인하고
# label encoding
X["habitat"].unique()
딕셔너리로 habitat컬럼 값: 바꿀값을 정의하고 map을 이용하여 habitat컬럼에서 habitat_dic 딕셔너리의 키값에 해당하는 값을 habitat_dic의 value값으로 바꿔준다. 즉 u는 1로, g는 2로... 바꿔준다.
habitat_dic = {
'u' : 1, # u를 1로 바꾸겠다.
'g' : 2, 'm' : 3, 'd' : 4, 'p' : 5, 'w' : 6, 'l' : 7
}
# X["habitat"]을 habitat_dic으로 바꾸겠다.
a = X["habitat"].map(habitat_dic).value_counts()
a
4. EDA (탐색적 데이터 분석)
plt.bar(a.index, a)
# 값의 편차를 줄이기 위해 log를 씀
plt.bar(a.index, np.log(a))
5. 모델 선택 및 하이퍼파라미터 튜닝
tree = DecisionTreeClassifier()
6. 학습
tree.fit(X_train, y_train)
7. 평가
print("train score : ", tree.score(X_train, y_train))
print("test score : ", tree.score(X_test, y_test))
과적합이 되어 점수가 1인것을 볼수있다.
tree모델의 특성 중요도 확인하기
- tree.feature_importances_
- 특성 중요도는 0~1 사이의 숫자로 이루어짐
- 특성 중요도의 총합은 1
- 0은 전혀 사용되지않았다는뜻, 1은 완벽하게 타깃 클래스를 예측했다는 뜻
# tree모델의 특성 중요도
fi = tree.feature_importances_
# 중요도를 데이터프레임형식으로 만들어서 보기좋게 하기
pd.DataFrame(fi, index=X_onehot.columns).sort_values(by=0, ascending= False)
모델링과는 상관없는 부분이지만 데이터 프레임 표를 보는데 표가 전부 출력이 안되고 위처럼 잘려보여서 전체를 다보고싶거나, 혹은 전부다 보여서 위처럼 줄여보고 싶을때 유용한 함수를 소개 할거에요.
pd.set_option()
위의 함수를 쓰면 됩니다.
모든 행을 출력하고 싶으면
pd.set_option('display.max_rows', None)
모든 열을 출력하고 싶으면
pd.set_option('display.max_columns', None)
모든 행 또는 열을 보고싶지않고 100개까지만 보고싶거나 10개까지만 보고싶으면 None에 원하는 숫자를 적으면 됩니다. 그러면 그만큼만 출력되요.
pd.set_option('display.max_columns', 10)
알고리즘 시각화
from sklearn.tree import export_graphviz
export_graphviz(tree, out_file='tree.dot',
class_names=['p','e'],
feature_names=X_onehot.columns,
impurity=False,
filled=True)
import os
os.environ["PATH"]+=os.pathsep+'C:/Program Files/Graphviz/bin'
# !pip install graphviz
import graphviz
with open('tree.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))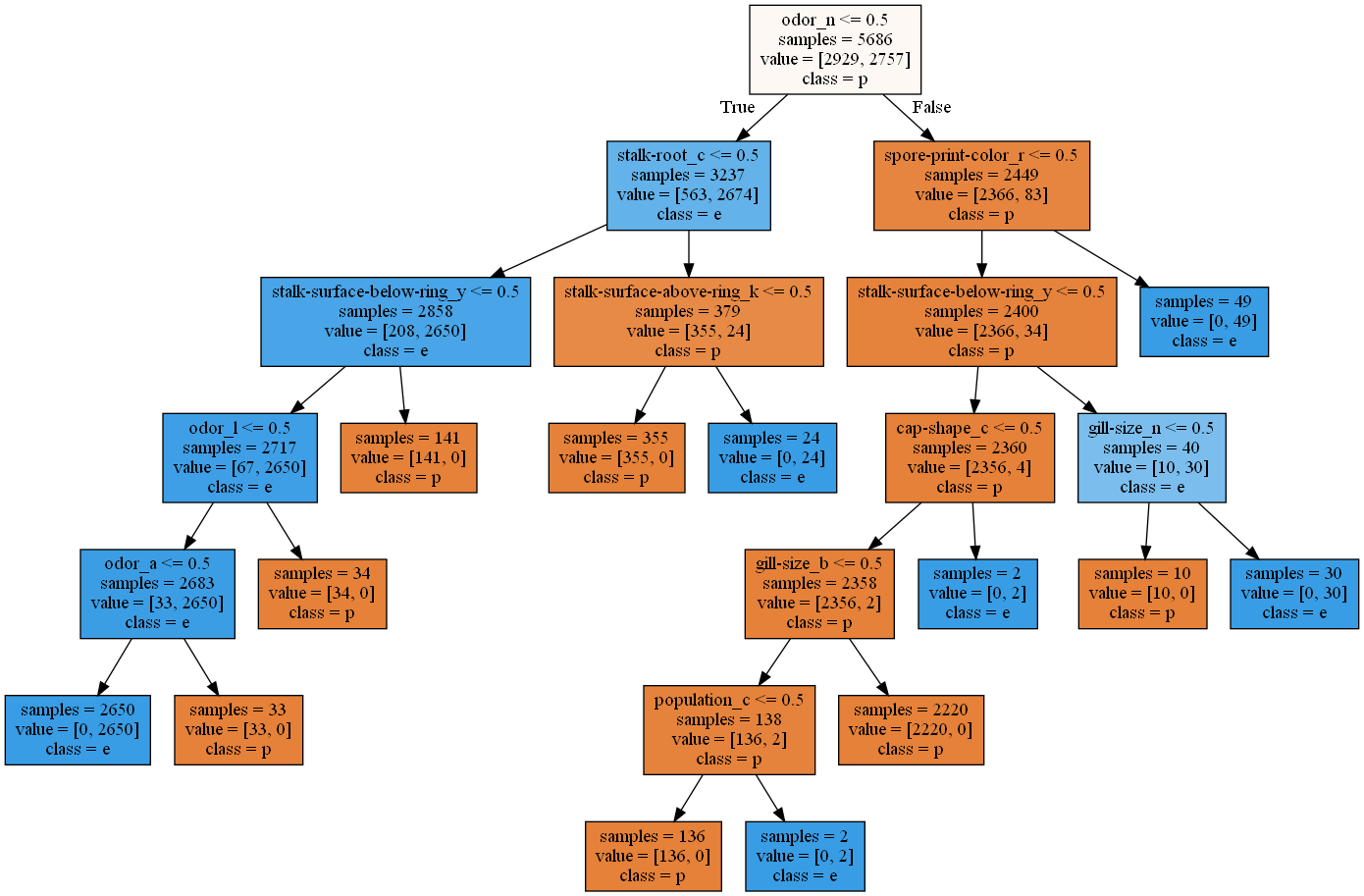
아래 코드는 알고리즘 시각화한 거를 pdf파일로 저장하고 싶을때 사용
# pdf파일 저장 코드
src = graphviz.Source(dot_graph)
src.view()
아래 코드는 알고리즘 시각화한 거를 사진으로 저장하고 싶을때 사용
# 사진으로 저장
from subprocess import check_call
check_call(['dot','-Tpng','tree.dot','-o','tree.png'])
위의 모델은 과적합이 되었으므로 트리의 깊이를 조절해서 과적합을 해결해보자.
그럼 다시 5부터 시작!
5-1 과적합 해결
# max_depth : 연속된 질문수 제한, 깊이 제한
# random_state=0
tree2 = DecisionTreeClassifier(max_depth=3)
tree2.fit(X_train, y_train)
print(f'train score : {tree2.score(X_train, y_train)}')
print(f'test score : {tree2.score(X_test, y_test)}')
과적합 해결후 알고리즘 시각화
export_graphviz(tree2, out_file='tree2.dot', #out_file로 dot파일을 만든다.
class_names=['p','e'],
feature_names=X_onehot.columns,
impurity= True, # gini출력 유무
filled=True) # filled: node의 색깔을 다르게
os.environ["PATH"]+=os.pathsep+'C:/Program Files/Graphviz/bin'
with open('tree2.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))
# 사진으로 저장
check_call(['dot','-Tpng','tree2.dot','-o','tree2.png'])
# gini가 0.5에 가까울수록 안좋고 0 또는 1에 가까울 수록 좋다.

교차 검증(cross-validation)
- 하이퍼파라미터 튜닝을 많이하면 그때 사용한 test에만 학습이 잘되서 다른 test를 넣으면 점수가 그만큼 안나오게 된다.
- 고정되어있는 test에 맞는 파라미터가 생기는 문제점을 해결할 방법이 교차검증이다.
- 교차검증은 여러번 학습과 평가를 진행, 그때마다 train과 test값에 변화를 줌
- 학습-평가 데이터 나누기를 여러번 반복하여 일반화 에러를 평가하는 방법이다.
k-fold cross-validation 동작 방법
- 데이터셋을 k개로 나눈다.
- 첫번째 세트를 제외하고 나머지에 대해 모델을 학습한다. 그리고 첫번째 세트를 이용해서 평가를 수행한다.
- 2번과정을 마지막 세트까지 반복한다.
- 각 세트에 대해 구했던 평가 결과의 평균을 구한다.

장/단점
- 데이터의 여러부분을 학습하고 평가해서 일반화 성능을 측정하기 때문에 안정적이고 정확하다.(샘플링 차이 최소화)
- 모델이 훈련 데이터에 대해 얼마나 민감한지 파악가능
- 데이터 세트 크기가 충분하지 않은 경우에도 유용하게 사용가능하다.
- 여러번 학습하고 평가하는 과정을 거치기 때문에 계산량이 많아진다.
5-2 모델선택 및 하이퍼파라미터 튜닝
교차검증 사용
# 5-2 모델선택
tree = DecisionTreeClassifier(max_depth = 3)
# 교차검증
# 사용한 모델 , 훈련용 문제(X_train), 훈련용 정답(y_train), 몇겹으로 교차검증을 할건지(cv)
# cv = 5이기 때문에 5개의 값이 나온다 = 5겹 교차검증
# 5개의 값이 모두 다르다. 이유 : 교차검증을 진행할때마다 train과 test데이터가 변화기 때문
# 5개의 값을 평균내서 test score를 예측해 볼 수 있다.
# 최적의 파라미터를 찾을 수 있다.
cross_val_score(tree, X_train, y_train, cv=5)
# cross_val_score(tree, X_train, y_train, cv=5).mean() # 평균값
tree2 = DecisionTreeClassifier(max_depth = 4, random_state=0)
cross_val_score(tree2, X_train, y_train, cv=5)
스마트인재개발원에서 진행된 수업내용입니다.
위에서 자료를 배포했지만 글중간에 있어서 못본사란들이 있을 수 있으니 한번더 올릴게요.
'파이썬 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 데이터 스케일링과 선형모델 [스마트인재개발원] (0) | 2021.06.24 |
|---|---|
| [머신러닝]분류용 선형 모델(Linear Model - Classification) [스마트인재개발원] (0) | 2021.06.22 |
| [머신러닝] KNN을 이용한 비만도 분석 (0) | 2021.06.07 |
| [머신러닝] 서울시 CCTV현황으로 선형회귀 구하기 (0) | 2021.06.04 |
| [머신러닝] 과대적합과 과소적합 & KNN(K- 최근접 이웃 알고리즘) (0) | 2021.06.04 |