
데이터 스케일링(Data Scaling)
- 특성(Feature)들의 범위(range)를 정규화 해주는 작업
- 특성마다 다른 범위를 가지는 경우 머신러닝 모델들이 제대로 학습되지 않을 가능성이 있다.
(KNN, SVM, Meural network모델, Clustering 모델 등)
예를 들어 시력과 키를 함께 학습 시킬 경우
키의 범위가 크기때문에 거리값을 기반으로 학습할 때 영향을 많이 준다.
- 데이터 스케일링 장점
- 특성들을 비교 분석하기 쉽게 만들어준다
- Linear Model, Neural network Model등에서 학습의 안정성과 속도를 개선시킨다.
- 하지만 특성에 따라 원해 범위를 유지하는게 좋을 경우는 scaling을 하지 않아도 된다.

- 데이터 스케일링 종류
StandardScaler
- 변수의 평균, 표준편차를 이용해 정규분포 형태로 변환(평균0, 분산1)
- 이상치에 민감하게 영향을 받는다.
RobustScaler
- 변수의 사분위수를 이용해 반환
- 이상치가 있는 데이터 변환시 사용 할 수 있다.
MinMaxScaler
- 변수의 Max값, Min값을 이용해 변환 (0~1 사이 값으로 변환)
- 이상치에 민감하게 영향을 받는다.
Normalizer
- 특성 벡터의 길이가 1이 되도록 조정(행마다 정규화 진행)
- 특성 벡터의 길이는 상관없고 데이터의 방향(각도)만 중요할때 사용
- 데이터 스케일링 주의점
- 훈련세트와 테스트세트에 같은 변환을 적용해야한다.
- 예를들어 StandardScaler의 경우 훈련세트의 평균과 표준편차를 이용해 훈련세트를 변환하고,
테스트세트의 평균과 표준편차를 이용해 테스트세트를 변환하면 잘못된 결과가 나온다.
코드로 스케일링 하는 방법
# srandardScaler 받아오기
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 범위 학습
scaler.fit(X_train)
# 학습된 범위로 변환
trans_X_train = scaler.transform(X_train)
trans_X_train
# test도 똑같이 진행
trans_X_test = scaler.transform(X_test)
trans_X_test이러면 trans_X_train, trans_X_test는 스케일링이 되었다.
선형 모델(Linear Model)
- 입력 특성에 대한 선형함수를 만들어 예측을 수행한다
- 다양한 선형 모델이 존재한다
- 분류와 회귀에 모두 사용 가능

다음은 선형 회귀 함수인데 x1, x2, x3...각각의 x들은 입력데이터의 p개 특성이다.
w1, w2, w3...각각의 w들은 각 특성별 가중치로 모두 동일하진 않다.

오차함수
- 각 사례의 오차를 계산하는 함수
- 즉 개별적인 오차 하나하나를 계산한다.

비용함수(Cost function)란
- 원래의 값과 가장 오차가 작은 가설함수를 도출하기 위해 사용되는 함수
- 최적화 이론에 기반을 둔 함수이다.
- 각각의 개별오차를 구하는게 아닌 전체 오차를 합쳐서 계산한다.
지도학습의 선형회귀 모델은 비용함수로 MSE(평균 제곱 오차)를 주로 사용한다.
(RMSE를 사용하기도 함)

비용함수에서 예측 값과 라벨의 오차를 절대값이 아닌 제곱으로 처리하는 이유
- 오차가 큰 경우에 더 큰 가중치를 주어 학습을 빠르게 처리
- MSE를 볼록함수(Convex Function)로 만들어 최적의 가중치를 효과적으로 찾기 위함
- 절대값은 미분불가능 수식
평균제곱오차가(MSE)가 최소가 되는 가중치(W)와 편차(b)를 찾는 방법
- 수학 공식을 이용한 해석적 방법(Ordinary Least Squares)
- 경사하강법(Gradient Descent Algorithm)
1. 수학 공식을 이용한 해석적 방법(Ordinary Least Squares)
LinearRegression클래스로 구현되어있어 LinearRegression클래스를 사용하면 된다.

2. 경사하강법(Gradient Descent Algorithm)
비용함수의 기울기(경사)를 구하여 기울기가 낮은 쪽으로 계속 이동하여 값을 최적화 시키는 방법이다.
미분의 극대/극소 개념을 이용하여 아래그림 같이 비용함수의 변화량을 상태를 파악하고 지속적으로 가중치를 갱신한다.

- 선형모델 장점
- 결과예측(추론)속도가 빠르다
- 대용량 데이터에도 충분히 활용 가능하다
- 특성이 많은 데이터 세트라면 훌륭한 성능을 낼수있다
- 선형모델 단점
- 특성이 적은 저차원 데이터에서는 다른 모델의 일반화성능이 더 좋을 수 있다.
-> 특성확장을 하기도 한다. - LinearRegression Model은 복잡도를 제어할 방법이 없어 과대적합되기 쉽다.
- 따라서 모델 정규화(Regularization)을 통해 과대적합을 제어한다.
모델 정규화
- 가중치(w)의 값을 조정하여 제약을 주는것
- L1규제: Lasso
w의 모든원소에 똑같은 힘으로 규제를 적용하는 방법. 특정 계수들은 0이된다.
특성선택이 자동으로 이루어진다 - L2규제: Ridge
w의 모든 원소에 골고루 규제를 적용하여 0에 가깝게 만든다.

Linear Model(선형모델) - Regression(회귀) 평가지표
회귀에서는 평가지표로 MSE, RMSE등을 사용할 수 있다.
그런데 MSE, RMSE값은 성능 지표로 사용하기에는 아쉬운 점이 있다.
ex) 몸무게를 예측했는데 MSE값이 3.8kg이라면 어느정도인지 알기어려움
sklearn에서는 Coefficient of Determination (R-squared)를 기본으로 사용한다.

선형회귀모델 선택 지표
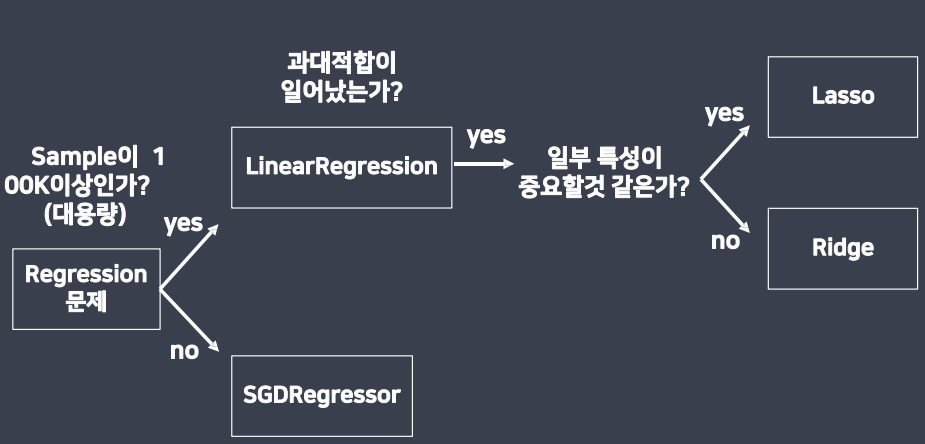
sample이 100k이상인가 말고 그냥 샘플이 대용량인가?만 보면된다.
이유는 100k인지 아닌지는 컴퓨터 마다 그게 대용량일수있고 대용량이 아닐수 있기때문이다.
Lasso는 특정 특성만 골라 사용할수있다. 따라서 일부 특성만 중요하면 Lasso 모든 특성이 중요하면 Ridge모델을 사용
성적으로 경사하강법과 수학공식 해석적방법 실습
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
성적 데이터 생성
X = [2, 4, 8, 9]
y = [20, 40, 80, 90]
data = pd.DataFrame({'시간': X, '성적': y})
data
1. 수학 공식을 이용한 해석적 모델
- LinearRegression
문제 데이터는 행렬벡터(2차원)로 이루어져 있기때문에 2차원으로 만들어야한다.
# LinearRegression 모델 받아오기
from sklearn.linear_model import LinearRegression
linear = LinearRegression()
# X(문제) - 시간 (2차원)
# y(정답) - 성적 (1차원)
linear.fit(data[['시간']], data['성적'])
# 입력특성(데이터)에 대해서 데이터들을 모두 반영한 예측함수를 만듬
print('가중치 :',linear.coef_)
print('절편:', linear.intercept_)
7시간 공부했을때 점수를 구해보자 (문제를 넣을때는 2차원으로 넣어야한다)
# 7시간 공부했을때의 점수는?
linear.predict([[7]])
2. 경사하강법
- 가중치(w)변화에 따른 비용함수(평균제곱오차 - MSE)값의 변화 그래프
- H(x)
- 예측함수
- y = wX + b의 모형인데 계산을 쉽게하기 위해 b=0으로 둘거다.
def h(w, x): # w : 가중치, x : 데이터 return w*x+0
비용함수(cost function)
- 평균제곱오차(MSE)
다음은 평균제곱오차 공식을 이용하여 cost라는 비용함수를 만들었다.
def cost(data, target, weight):
# data - 문제
# target - 정답
# weight - 가중치
y_pre = h(weight, data)
# 예측함수에 가중치와 문제를 넣어서 예측값을 출력
# 예측값 - 실제값 = 오차
# y_pre - target = 오차
# ** 2 : 제곱
# .mean() 평균
return ((y_pre - target)**2).mean()# 비용함수 - 평균제곱오차
# 평균제곱오차의 값이 0에 가까울수록 예측을 잘한 함수
cost(data['시간'], data['성적'], 10)(data['시간'], data['성적'], 12)
# 가중치에 따른 비용함수 그래프
# 그래프를 그릴 가중치 범위 ( -10~30)
weight_arr = range(-10, 31)
# 비용함수(MSE)값을 담을 리스트 생성
cost_list = []
for w in weight_arr:
c = cost(data['시간'], data['성적'], w)
cost_list.append(c)
# 그래프 그리기
plt.plot(weight_arr, cost_list)
plt.show()
SGDRegressor(경사하강법)을 사용

학습률이란 가중치 최저점을 찾기위해 이동을 할때 얼마만큼 간격(거리)을 두고 찾으러 가는지이다.
예를들어 10km를 걷는데 누구는 한걸음당 100cm로 걷고 누구는 걸음당 60cm로 걷는식이다.
만약 학습률이 너무 크면 위의 왼쪽 그림처럼 효율이 떨어지고 학습률이 너무 작으면 극소지역점에 빠질수있다.
즉, 아래 그림과 같이 실제로 가중치 최저점을 찾아야되는데 최저점이 아닌 극소지역점이란 곳에 빠진후 학습률이 너무 작기 때문에 빠진상태에서 나올질 못하는 거다.

자세한 설명은 아래 사이트에서 확인
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDRegressor.html
sklearn.linear_model.SGDRegressor — scikit-learn 0.24.2 documentation
scikit-learn.org
from sklearn.linear_model import SGDRegressor
sgd = SGDRegressor(
max_iter = 1000, # 가중치 업데이트 횟수
eta0=0.01, #학습률(Learning rate),
verbose = 1 # 학습과정확인
)sgd.fit(data[['시간']], data['성적'])
fit으로 학습시키면 가중치 최저점을 찾기위해 컴퓨터가 경사하강법으로 계속 돌아가는데
내가 가중치 업데이트 횟수를 1000으로 설정했어도 loss의 변화가 거의없다고 판단하면 알아서 학습을 멈춘다.
위에서는 1000으로 설정했지만 147번만 학습한걸 볼 수있다.
print('가중치 : ', sgd.coef_)
print('절편 : ', sgd.intercept_)
LinearRegression을 보스턴 주택값 데이터로 실습해보기
LinearRegression
- 수학적 공식을 이용한 모델
- 비용함수(평균제곱오차)가 최소가 되는 지점을 계산을 통해서 한번에 출력
- 출력값을 수정할 방법이 없기 때문에 과대/ 과소 적합을 해소할 수 없다
- LinearRegression + 정규화(규제) 를 통해 과대/과소 적합을 해소
- Lasso : 가중치를 일정량만큼 규제(ex 전부 -2만큼 규제)
- 특정 계수들은 0이 됨
- Ridge : 가중치를 일정한 퍼센트(%)만큼 규제 (ex 전부 -20%만큼 규제)
- 계수들이 0이 되지않고 0에 가까워진다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 보스턴 주택값 데이터
from sklearn.datasets import load_boston
boston = load_boston()
boston.keys()
문제와 정답 나누기
# 문제(X)
boston_df = pd.DataFrame(boston.data, columns = boston.feature_names)
boston_df.head()
# 정답(y)
house_price = boston.target
house_price
train, test로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
boston_df, house_price, test_size=0.3, random_state=3)
선형회귀 모델
from sklearn.linear_model import LinearRegression
linear = LinearRegression()
linear.fit(X_train, y_train)
print("train score :", linear.score(X_train, y_train))
print("test score:", linear.score(X_test, y_test))
특성 확장하기
X_train.shape # 인덱스와 컬럼이 (354, 13)인걸 확인특성확장은 기존 컬럼이 1 2 3 4 5...이런식이면 새로운 컬럼은 아래와 같은식으로 만들거다.
1*1 1*2 1*3 1*4 1*5...
2*1 2*2 2*3 2*4 2*5...
.
.
extend_X_train = X_train.copy()
for col1 in X_train.columns: # 13번 반복
for col2 in X_train.columns: # 13번 반복
extend_X_train[col1 + 'x' + col2] = X_train[col1] * X_train[col2]
# 컬럼의 수는 13 + 13*13(169) = 182개가 만들어진것을 확인할수있다.
extend_X_train.shape
extend_X_test = X_test.copy()
for col1 in X_test.columns: # 13번 반복
for col2 in X_test.columns: # 13번 반복
extend_X_test[col1 + 'x' + col2] = X_test[col1] * X_test[col2]
extend_X_test.shapelinear.fit(extend_X_train, y_train)
print('train score: ', linear.score(extend_X_train, y_train))
print('test score: ', linear.score(extend_X_test, y_test))
정규화 하기
from sklearn.linear_model import Ridge, Lasso
ridge = Ridge()
lasso = Lasso()
alpha = 규제를 가할 양, 기본값: 1
규제가 커졌다 = 컬럼들의 사용량이 줄어들었다 -> 학습량이 줄어든다. -> 그래프 왼쪽으로 이동 -> 과소적합에 걸릴 가능성이 커짐,과대적합을 피할 수 있다.
규제가 작아진다 = 컬럼들의 사용량이 많아진다 -> 학습량이 늘어난다. -> 그래프 오른쪽으로 이동 -> 과대적합에 걸릴 가능성이 커짐, 과소적합을 피할수있다.
Ridge와 lasso사용시 규제를 매우 약하게 주면 LinearRegression모델과 동일해짐
이유: Ridge와 lasso가 LinearRegression모델의 정규화를 위해 사용하는 것이므로 규제를 적게주면 정규화 효과가 거의없다
# alpha = 규제를 가할 양
ridge = Ridge(alpha=0.1)
ridge.fit(extend_X_train, y_train)
print('train score: ', ridge.score(extend_X_train, y_train))
print('test score: ', ridge.score(extend_X_test, y_test))
print('사용된 특성의 개수 :', np.sum(ridge.coef_!=0))
# ridge는 모든원소에 골고루 규제를 주기 때문에 알파에 어떤값을 넣어도 전체컬럼수가 나온다.
lasso = Lasso(alpha= 0.0001)
lasso.fit(extend_X_train, y_train)
print('train score: ', lasso.score(extend_X_train, y_train))
print('test score: ', lasso.score(extend_X_test, y_test))
print('사용된 특성의 개수 :', np.sum(lasso.coef_!=0))
위에서 np.sum(lasso.coef_!=0) 가 뭔지 설명하자면
.coef_ 는 가중치를 출력하는 함수이다. lasso.coef_는 lasso의 가중치를 출력
lasso.coef_의 결과가 0이면 사용되지 않는 컬럼이고 0이 아니면 사용되는 컬럼이다.
(위에서 설명했지만 lasso는 사용할 특성과 사용하지 않을 특성을 고를수있다.)
lasso.coef_!=0를 사용하여 0이 아닌것들의 갯수를 세면 몇개의 컬럼(특성)이 사용되었는지 알수있다.
0이면 True, 0이 아니면 False로 나올거다.
이를 sum함수를 사용하여 합계를 구하면
즉, np.sum(lasso.coef_!=0)를 사용하면 True는 1의 값을 가지고 False는 0의 값을 가져서
결과가 True의 개수만큼 반환된다. 따라서 특성의 개수만큼 반환되어 특성(컬럼)의 개수를 알 수 있다.
스마트인재개발원에서 진행된 수업내용입니다.
'파이썬 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 머신러닝 기초 - 행렬과 벡터 [광주인공지능학원] (0) | 2021.08.22 |
|---|---|
| [머신러닝]분류용 선형 모델(Linear Model - Classification) [스마트인재개발원] (0) | 2021.06.22 |
| [머신러닝] Decision Tree(결정트리) [스마트인재개발원] (0) | 2021.06.17 |
| [머신러닝] KNN을 이용한 비만도 분석 (0) | 2021.06.07 |
| [머신러닝] 서울시 CCTV현황으로 선형회귀 구하기 (0) | 2021.06.04 |