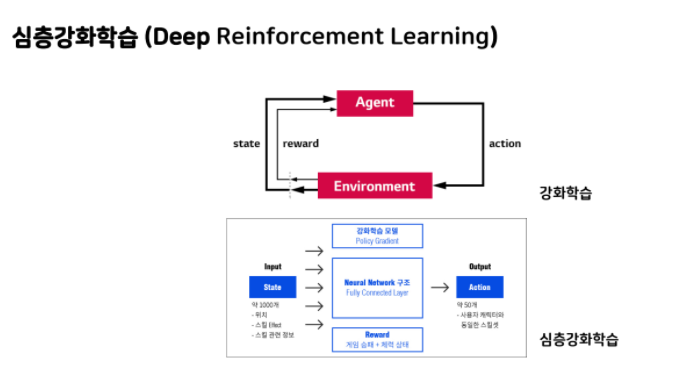
오늘은 광주인공지능학원에서 진행된 알파벳 맞추기를 진행하겠습니다 (본 글의 자료는 광주인공지능학원에서 제공되었습니다.) CNN 입력값 파라미터 (sample, height, weight, chanel) sample: 데이터의 수 height: 세로 weight: 가로 chanel: 1 (grayscale) 3 (RGB) 4(RGBA) * A 투명도 RNN 파라미터 (sample, timesteps, features) sample: 데이터의 수 timesteps: 몇 단계로 이루어 질것인지 내일 주식가격 예측을 위해서 과거 5일의 데이터를 가져옴: 5 나는 오늘 집에 가서 밥을 __: 5 features: 특징의 수 예를들어) 음악: 미 레 도 레 _ 음계: features: 1 음계, 박자: featur..