
분류용 선형 모델 공식

분류용 선형 모델 특징
- 특성들의 가중치 합이 0보다 크면 class를 +1(양성클래스)
0보다 작으면 클래스를 -1(음성클래스)로 분류한다 - 분류용 성형모델은 결정 경계가 입력의 선형함수
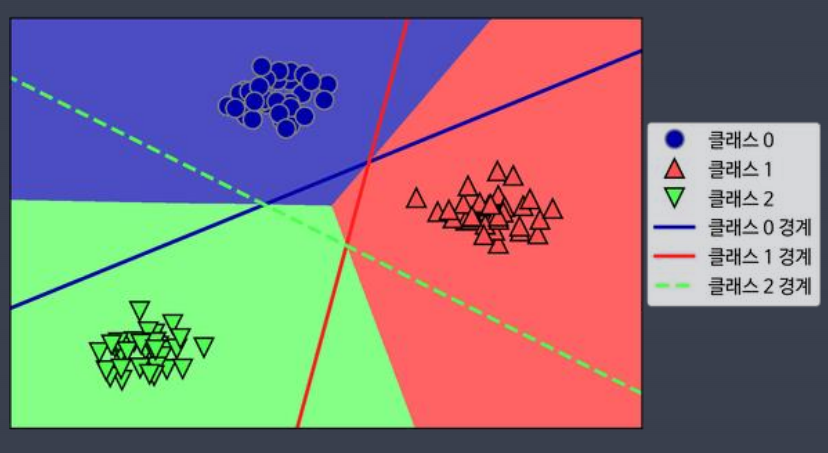
- 일대다 방법을 통해 다중 클래스 분류
다중 클래스를 분류하려면 선을 많이 그려야 한다.
Logistic Regression
- 회귀공식을 사용해서 Regression이라는 이름이 붙음
- 결정경계가 선형이기 때문에 선형 모델
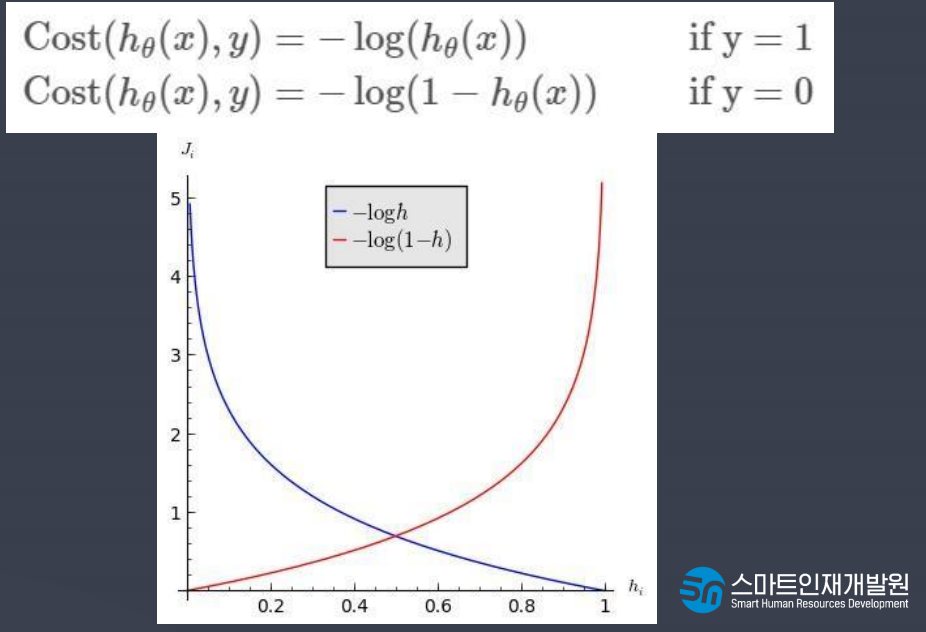
- 시그모이드 함수의 최적선을 찾고 반환값을 확률로 간주
- 선형함수의 결과값을 시그모이드 함수(Logistic Function)을 이용해 0과 1로 변환
- 시그모이드 함수
시그모이드 함수를 사용하면 직선을 곡선으로 바꿔준다.
값의 범위가 0~1 사이


- 주요 매개변수(하이퍼파라미터)
- 선형 분류 모델: C
(값이 클수록 규제가 약해진다.) - 기본적으로 L2쥬게를 사용, 하지만 중요한 특성이 몇개 없다면 L1규제를 사용해도 무방
(주요 특성을 알고 싶을때 L1규제를 사용하기도 한다.)
Support Vector Machine (SVM)
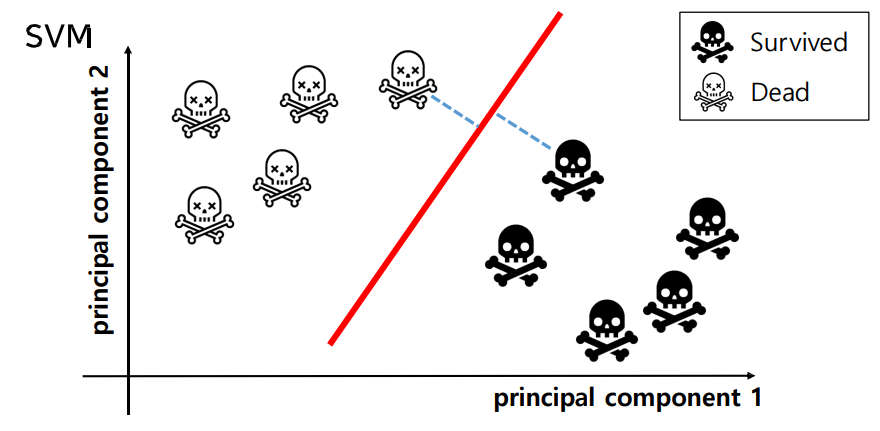
그림에서는 Survived와 Dead가 서포트 벡터들이다.
서포트 벡터와의 거리가 똑같은 지점에 결정경계를 그린다.
규제를 강화하면 서포트 벡터들이 멀어지고 완화하면 가까워진다.
- 장단점
- 선형 모델은 학습 속도가 빠르고 예측도 빠르다
- 매우 큰 데이터 세트와 희소(sparse)한 데이터 세트에서도 잘 등장한다.
- 특성이 많을수록 더울 잘 동작한다.
- 저차원(특성이 적은)데이터에서는 다른 모델이 더 좋은 경우가 많다.
- 주요 매개변수(하이퍼파라미터)
- 회귀 선형 모델 : alpha (값이 클수록 규제 강화)
- 선형 분류 모델: C (값이 클수록 규제 완화)
- 기본적으로 L2규제를 사용, 하지만 중요한 특성이 몇개 없다면 L1규제를 사용해도 무방하다.
(주요 특성을 알고 싶을 때 L1 규제를 사용하기도 한다.)
| 모델 | 파라미터 | 파라미터 값 커짐 | 파라미터 값 작아짐 |
| 분류 | alpha | 규제강화 | 규제완화 |
| 선형 | C | 규제완화 | 규제강화 |
분류 평가 지표
분류는 정확도를 통해서 판단한다.
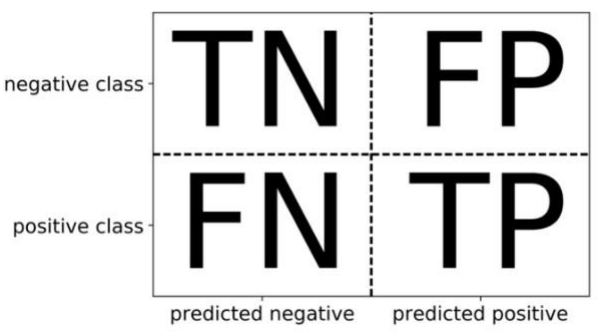
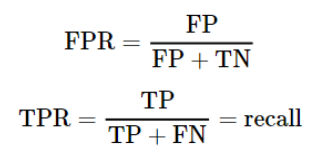
TN: 실제 N이고 N이라고 예측
FP: 실제 N이고 P라고 예측
FN: 실제 P이고 N이라고 예측
TP: 실제 p이고 p라고 예측
정확도(Accuracy) = 전체 중에서 정확하게 맞춘 비율
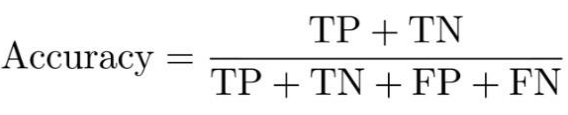
재현율(Recall) = 실제 양성(p)중에 예측 양성(p)의 비율

정밀도(Precision) = 예측 양성(p) 중에서 실제 양성(p) 비율
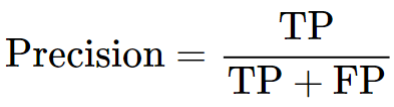
재현율과 정밀도는 상호보완적 관계라 하나가 올라가면 다른 하나가 내려간다.
정밀도와 재현율이 조화를 이룰 때 제일 좋은 지표이다.
정밀도와 재현율의 가중조화평균(weight harmonic average): F점수(F-score)
정밀도에 주어지는 가중치를 베타(beta)라고 한다.
Fβ=(1+β2)(precision×recall)/(β2precision+recall)
베타가 1일때 정밀도와 재현율의 조화평균 = F1 - score
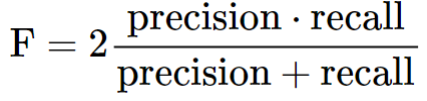
낮은 재현율보다 높은 정밀도를 선호하는 경우
애매한거는 제외하고 확실한것만 고려해야 될때.
예를들어) 어린아이에게 안전한 동영상(양성)을 걸러내는 분류기를 훈련 시킬 경우 좋은 동영상이 많이 제외되더라도(낮은 재현율) 안전한 것들만 노출시키는 9높은 정밀도)분류기가 더 좋다.
낮은 정밀도보자 높은 재현율을 선호하는 경우
애매한것도 고려해야 될때.
예를들어) 감시 카메라로 좀도둑(양성)을 잡아내는 분류기를 훈련시킬 경우 경비원이 잘못된 호출을 종종 받지만(낮은 정밀도) 거의 모든 좀도둑을 잡는(높은 재현율)분류기가 더 좋다.
ROC curve
이 지표는 요즘 사용을 하지않는 추세라 이런게 있다 정도만 확인하고 넘어가자.

손글씨 데이터 분류 실습
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
digit_data = pd.read_csv("digit_train.csv")
# 42000개의 손글씨 데이터
# 정답포함해서 785개의 컬럼이 있다
# 정답 제외 789개 컬림이 존재 = 28*28 = 784
digit_data.shapeshape로 행이 42000, 컬럼이 785개 있다는걸 확인할수있다.
데이터의 0행의 값을 img0변수에 넣어서 보자.
일단 히스토그램을 그려서 값의 분포를 확인
img0 = digit_data.iloc[0,1:]
plt.hist(img0)
plt.show()
.imshow
250에 가까울수록 노랑색, 0에 가까울수록 보라색으로 표시된다.
plt.imshow(img0.values.reshape(28,28))
plt.show()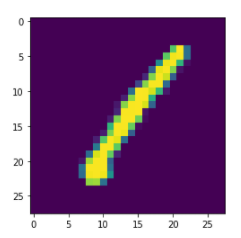
위의 그래프를 gray로 바꿈
250에 가까울수록 흰색, 0에 가까울수록 검정색으로 표시된다.
plt.imshow(img0.values.reshape(28,28), cmap="gray")
plt.show()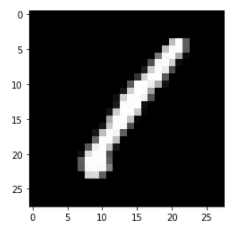
5000장을 추출해서 학습시켜보기
X = digit_data.iloc[:5000, 1:]
y = digit_data.iloc[:5000, 0]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=3)
from sklearn.linear_model import LogisticRegression
logi = LogisticRegression()
logi.fit(X_train, y_train)
print("train score:", logi.score(X_train, y_train))
print("test score:", logi.score(X_test, y_test))
from sklearn.svm import LinearSVC
svm = LinearSVC()
svm.fit(X_train, y_train)
print("train score:", svm.score(X_train, y_train))
print("test score:", svm.score(X_test, y_test))
# 50, 51
logi.predict_proba(X_test[50:52])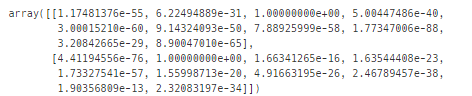
img50 = X_test.iloc[50]
plt.imshow(img50.values.reshape(28,28), cmap='gray')
plt.show()
분류 평가 지표 확인하기
from sklearn.metrics import classification_report
pre_logi = logi.predict(X_test)
print(classification_report(pre_logi,y_test))
결과에서 precision을 보면 0이라고 예측한 데이터의 92%가 실제로 0이었고 1이라고 예측한 데이터의 96%가 실제로 1이었음을 알 수 있다. 또한 recall을 보면 실제 0인 데이터 중의 89%가 0으로 판별되었고 실제 1인 데이터 중의 94%가 1로 판별되었음을 알 수 있다.
- macro: 단순평균
- weighted: 각 클래스에 속하는 표본의 갯수로 가중평균
- accuracy: 정확도. 전체 학습데이터의 개수에서 각 클래스에서 자신의 클래스를 정확하게 맞춘 개수의 비율
스마트인재개발원에서 진행된 수업내용입니다.
'파이썬 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 머신러닝 기초 - 행렬과 벡터 [광주인공지능학원] (0) | 2021.08.22 |
|---|---|
| [머신러닝] 데이터 스케일링과 선형모델 [스마트인재개발원] (0) | 2021.06.24 |
| [머신러닝] Decision Tree(결정트리) [스마트인재개발원] (0) | 2021.06.17 |
| [머신러닝] KNN을 이용한 비만도 분석 (0) | 2021.06.07 |
| [머신러닝] 서울시 CCTV현황으로 선형회귀 구하기 (0) | 2021.06.04 |